Architecture
Memori is a modular memory layer for AI applications. You connect your LLM client, set attribution, point Memori at your database, and it handles everything else — storage, augmentation, knowledge graph construction, and recall. All data stays on your infrastructure.
System Overview
Core Components
Memori Core — The central coordinator between your application and your database. Manages attribution, coordinates storage and augmentation, provides LLM wrappers, and exposes the Recall API.
LLM Provider Wrappers — Wraps your existing LLM client transparently. Intercepts calls, captures messages and responses, persists conversation data to your database. Supports sync, async, and streaming.
Attribution System — Tags every memory with who created it and in what context. Tracks three dimensions: entity (the user), process (the agent), and session (the conversation thread).
Storage System — Stores all data in your database with no external dependencies. Supports SQLAlchemy sessionmaker, DB-API 2.0 connections, Django ORM, and MongoDB. Works with SQLite, PostgreSQL, MySQL, MariaDB, Oracle, CockroachDB, and OceanBase, including providers like Neon, Supabase, and AWS RDS/Aurora.
Advanced Augmentation — Turns raw conversations into structured memories. Extracts facts, preferences, and skills, generates vector embeddings locally, and builds a knowledge graph. Runs asynchronously with zero latency impact.
Configuration
Setting up Memori requires a database connection and attribution:
import sqlite3
from memori import Memori
from openai import OpenAI
def get_connection():
return sqlite3.connect("memori.db")
client = OpenAI()
mem = Memori(conn=get_connection).llm.register(client)
mem.attribution(entity_id="user_123", process_id="my_agent")
mem.config.storage.build()
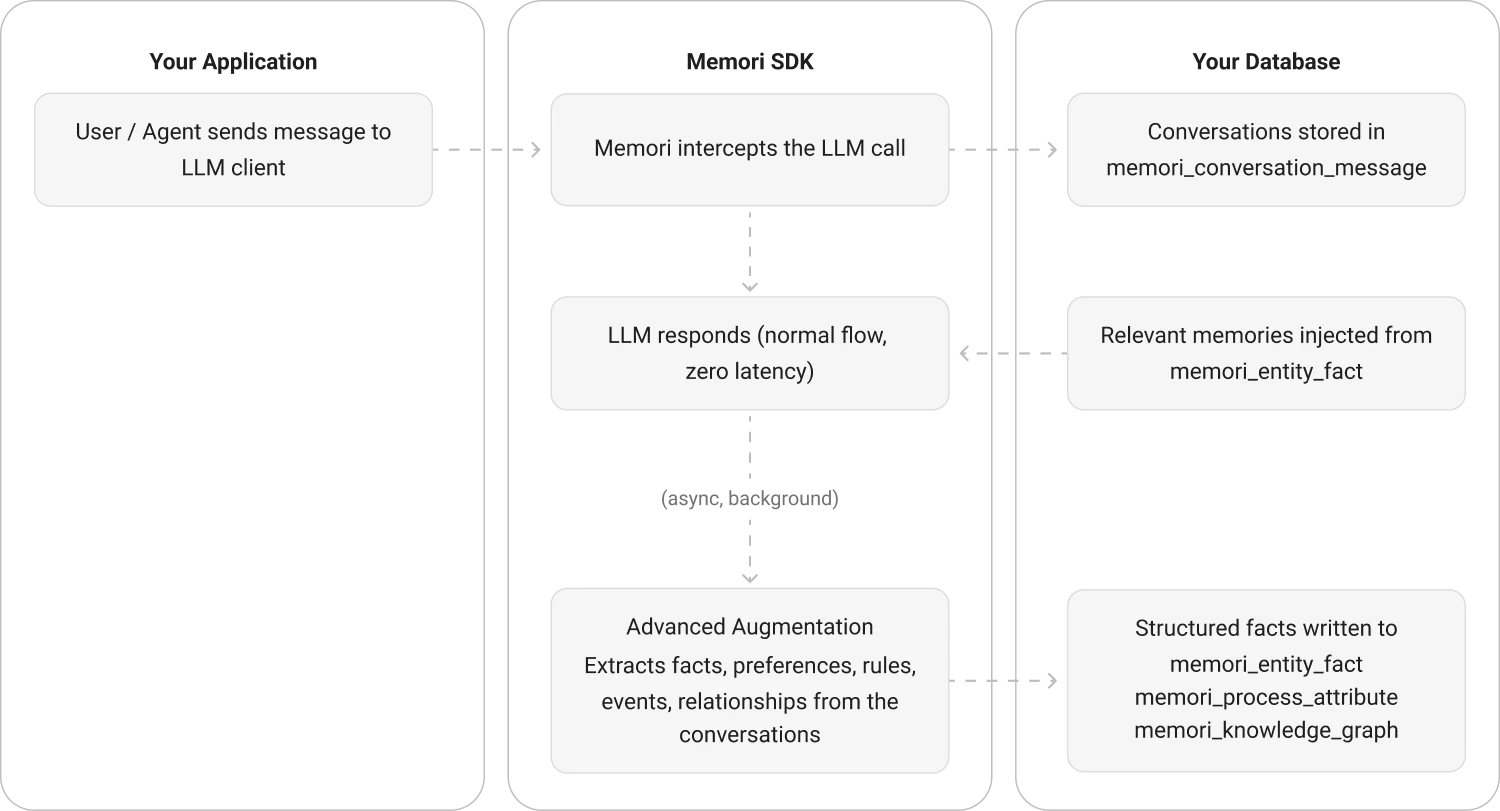
Data Flow
-
Conversation Capture — Every LLM call through the wrapped client is captured and stored in your database. Your app gets the response immediately.
-
Attribution Tracking — Attribution links every conversation to a specific entity and process so memories are properly scoped and indexed.
-
Augmentation — After a conversation completes, Memori processes it asynchronously — extracts facts, generates embeddings locally, and builds knowledge graph triples.
-
Recall — On the next LLM call, Memori surfaces the right memories at the right time: semantic search, intelligent ranking and decay, and seamless injection of the most relevant context into the system prompt so your AI stays contextually aware.